音频处理笔记
音频处理笔记
1 介绍
声音
声音由空气压力的变化而产生。声音信号通常由不同频率的信号组合而成。
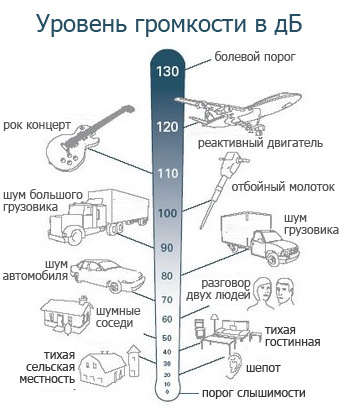
为了能够将声音输入模型中,我们需要将声波数字化,即将信号转换为一系列的数字。这是通过以固定时间间隔测量声音的振幅来完成的,即采样。采样率是每秒采样出的样本数,常见的采样率约为每秒44100个样本。
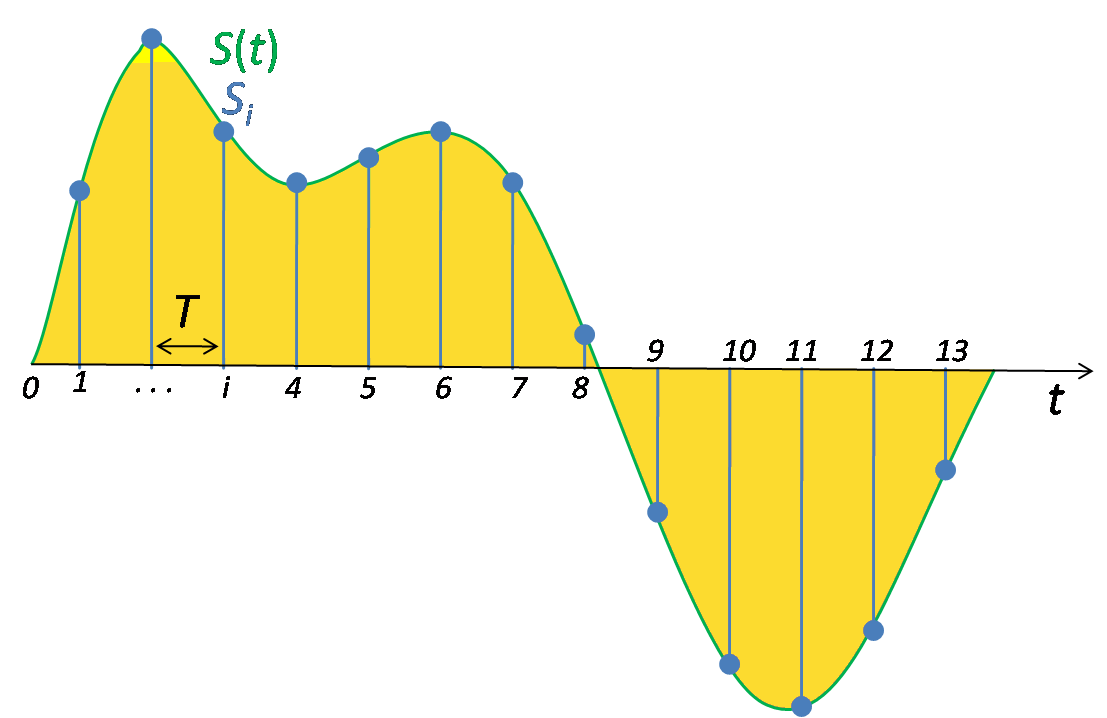
音频数据处理方式
过去的音频机器学习应用程序依赖于传统的数字信号处理技术来提取特征。例如,用语音学概念分析音频信号以提取音素等元素。所有这些方法都大量特定领域的专业知识。
随着深度学习的发展,处理音频的方式不再使用传统的音频处理技术,无需通过大量手动操作和自定义来生成特征,而是采用由音频生成频谱图的技术。
频谱Spectrum
频谱是组合产生信号的一组频率。频谱绘制了信号中存在的所有频率以及每个频率的强度或幅度。信号中最低的频率称为基频。基频的整数倍频率称为谐波。
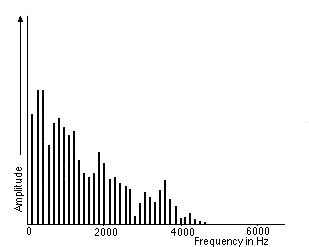
通常我们看的波形是信号的时域表示,表示振幅随时间的变化。频谱是信号的频域表示,表示再某个时刻,振幅与频率的关系。
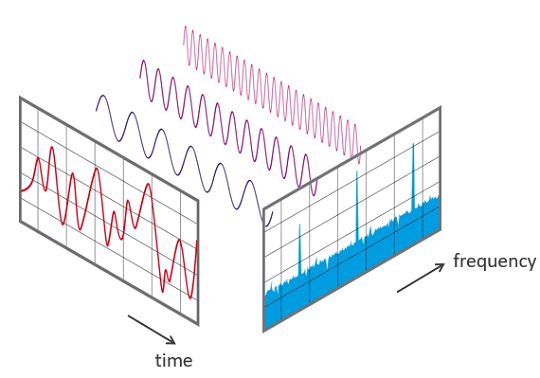
频谱图spectrogram
声音信号的组成频率是随时间变化的,因此频谱随时间而变化。
频谱图是音频信号的等效紧凑表示,就像信号的“指纹”,它将音频数据的基本特征捕获为图像。
频谱图绘制了时间与频谱的关系,x轴为时间,y轴为频率。
频谱图使用不同的颜色来表示频率的幅度或强度。颜色月亮,信号的能量就越高。频谱图每个垂直的“切片”本质上是信号在该时刻的频谱,并表示信号强度如何分布在该时刻信号中的每个频率中。
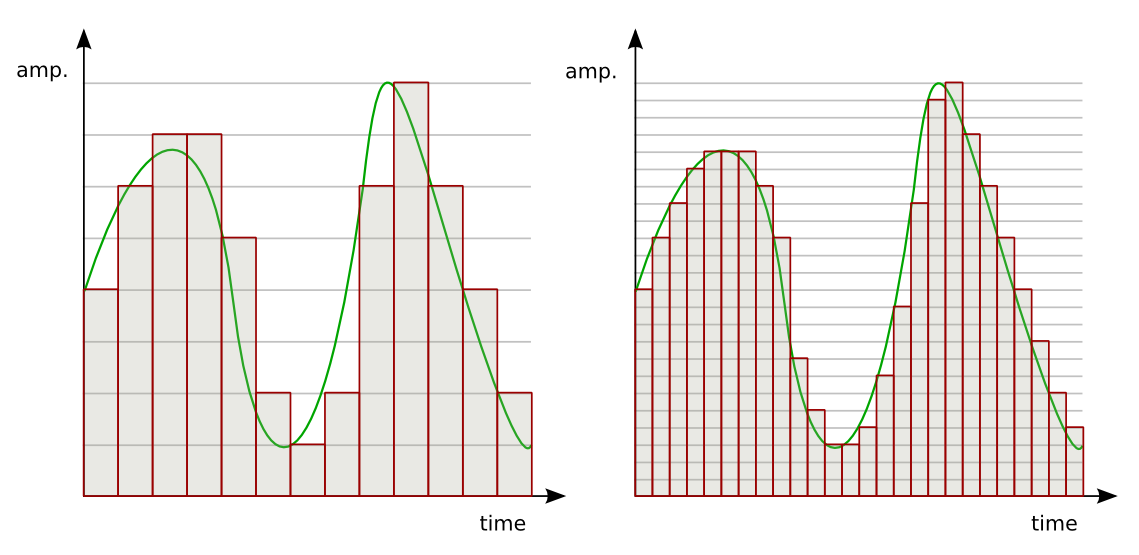
频谱图是使用傅立叶变化将信号分解为其组成频率而生成的。首先将声音信号分为一系列持续时间很短的信号片段;然后对每个段应用傅立叶变换获取该段的组成频率,并显示信号中存在的每个频率的幅度;最后将所有这些片段的傅立叶变换组合成一个图即为频谱图。
人耳
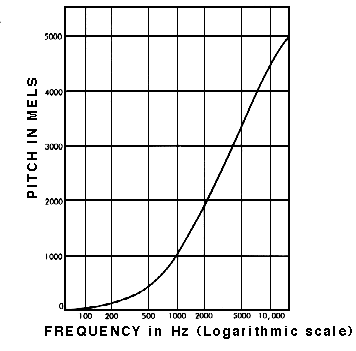
我们通常所说的“音高”,其实为声音的频率。音调高的声音具有比音调低的声音更高的频率。人类不会线性感知频率,与高频相比,人类对低频之间的差异更敏感。
我们通常所说的“响度”,其实为声音的振幅。人们对振幅的感知同样也不是线性的。
事实上,人耳对频率和响度的感知都是对数的。
为了以真实的方式处理声音,在处理数据中的频率和振幅时,需要使用对数标度,即梅尔标度(频率)和分贝标度(振幅)。这正是Mel Spectrogram的目的。
2 处理
音频信号的内存表示
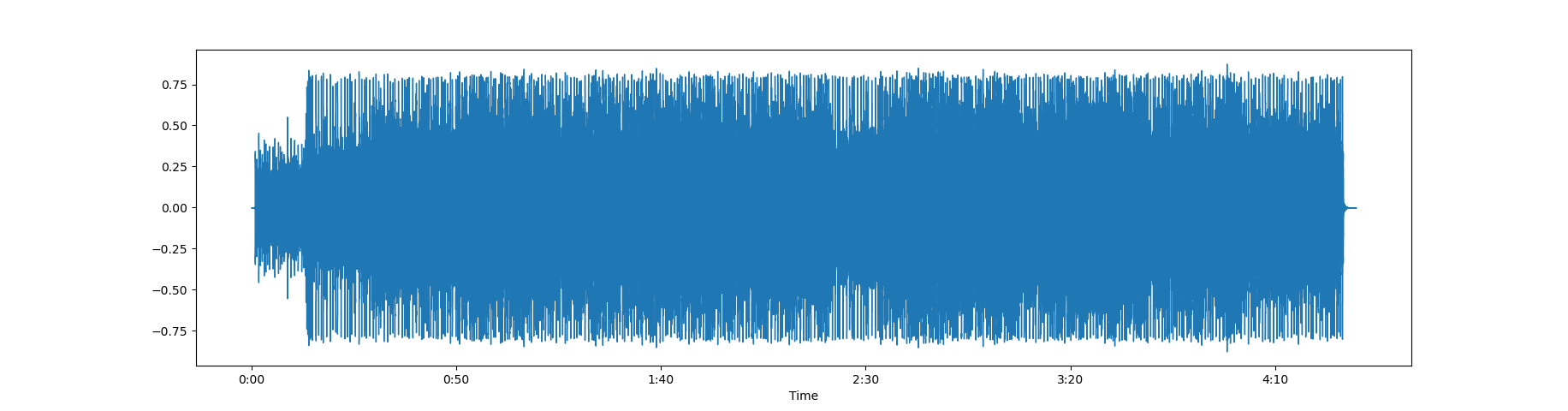
在内存中,音频表示为数字的时间序列,表示每个时间步长的振幅。例如,如果采样率为 44100,则一秒的音频剪辑将有 44100 个数字。由于测量是在固定的时间间隔进行的,因此数据仅包含振幅数字而不包含时间值。给定采样率,我们可以计算出每次振幅数测量是在什么时刻进行的。
位深度(bit-depth)告诉我们每个样本的幅度测量值可以取多少个可能的值。例如,位深度为 16 表示振幅数可以介于 0 和 65535 (2 16 - 1) 之间。位深度影响音频测量的分辨率——位深度越高,音频保真度越好。
waveform
1 | |
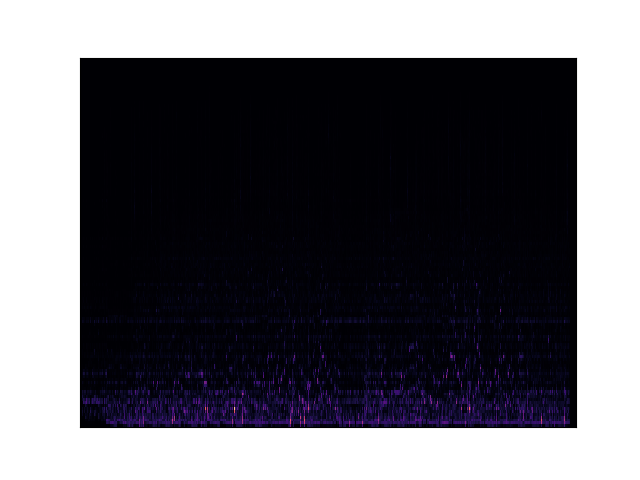
spectrogram
1 | |

显然,在该频谱图上看不到太多信息。发生这种情况的原因是人耳感知声音的方式是对数的,人类能够听到的大部分声音都集中在一个狭窄的频率和振幅范围内。
Mel Spectrogram
相对于常规的频谱图,梅尔频谱图有两个重要的变化:
y轴使用梅尔刻度而不是频率
使用Decibel Scale而不是Amplitude来指示颜色
深度学习通常使用梅尔频谱图。
1 | |
这好多了,但大部分仍然很暗,可见没有携带足够的有用信息。因此,我们修改它以分贝比例而不是振幅。
1 | |
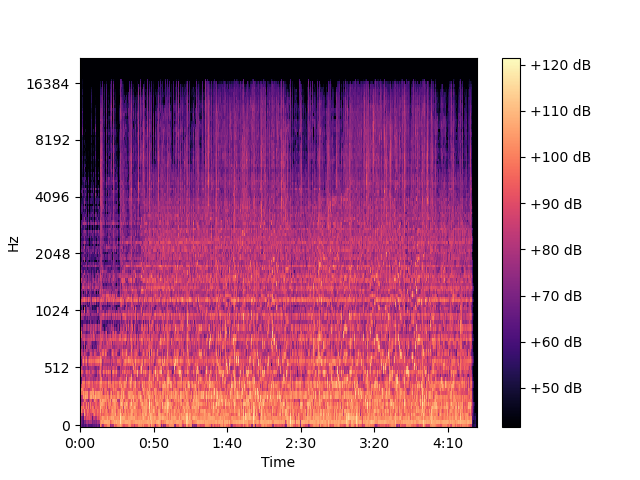
这就是我们真正想要的。
优化
傅立叶变换
离散傅立叶变换(DFT):计算成本高,实践中较少用。
快速傅立叶变换(FFT):计算音频信号整个时间序列的整体频率分量。但无法得知频率分量在音频信号中随时间的变化情况。
短时傅里叶变换(STFT):使用滑动时间窗口将音频信号分解成更小的部分,对每个部分进行FFT,最终组合在一起。能够捕获频率随时间的变化。
STFT将音频信号分别沿时间轴和频率轴分为多个部分。它对整个频率范围进行划分,在梅尔尺度中分为等距的频带。STFT对每个时间段计算每个频带的振幅或能量。
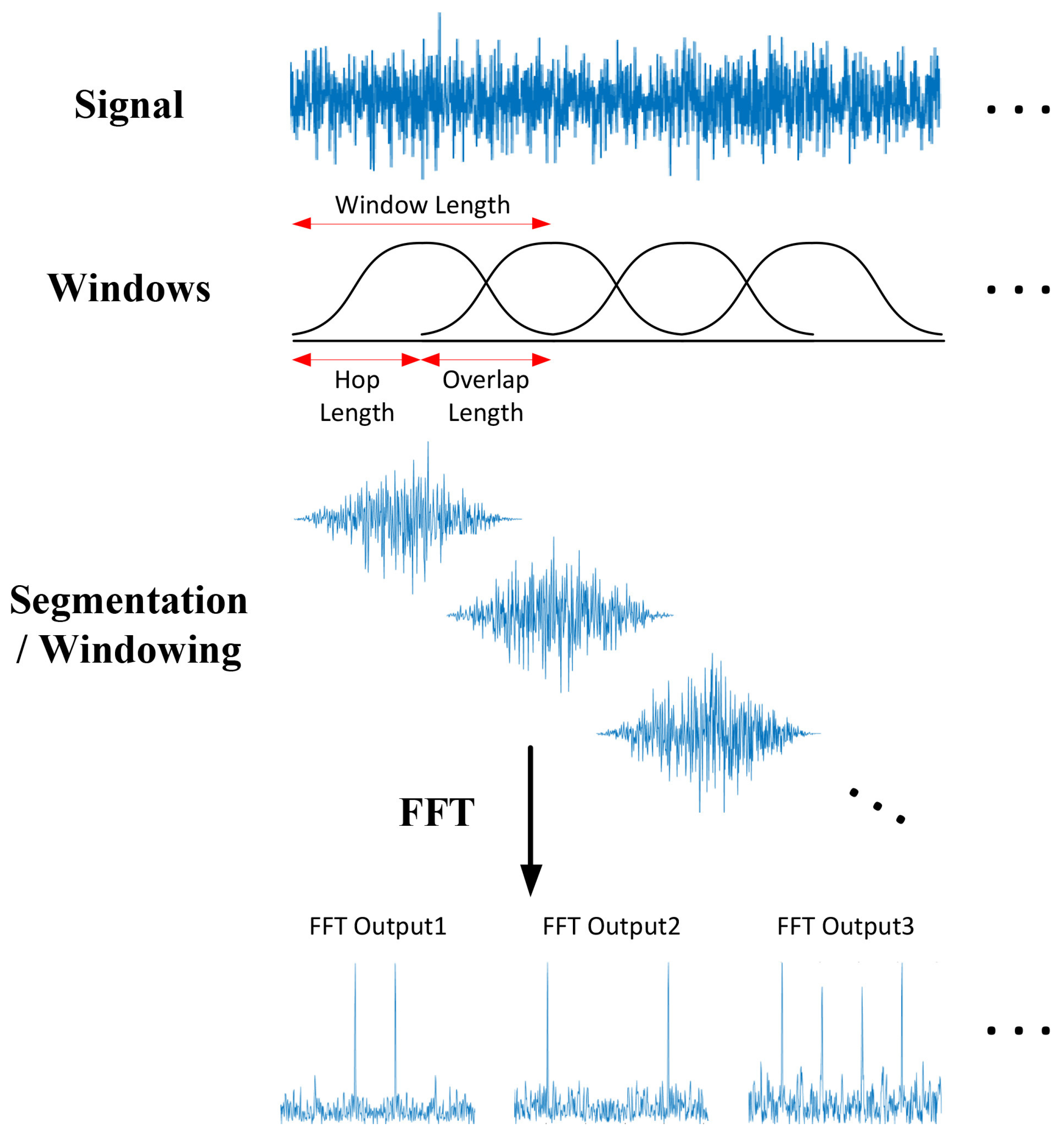
1 | |
梅尔谱图超参数
用于调整梅尔谱图的超参数,使用Librosa的参数名称。(其他库也具有等效参数)
频段
fmin:最小频率
fmax:要显示的最大频率
n_mels:频带数(即梅尔箱)。这是频谱图的高度
时间段
n_fft:每个时间段的窗口长度
hop_length:每一步滑动窗口的样本数。频谱图宽度=样本总数/hop_length
MFCC(梅尔频率倒谱系数)
对于处理人类语音的问题,MFCC有时效果更好。
MFCC可以从梅尔谱图中选择与人类说话最常见的频率相对应的频带的压缩表示。
1 | |
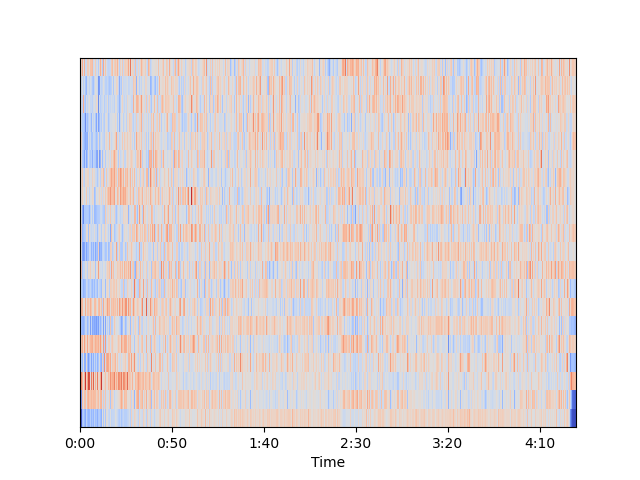
MFCC从音频中提取出的特征比梅尔谱图更少,这些特征与捕捉声音的基本质量最相关。
频谱图增强
应用于图像的变换不适用于频谱图。例如翻转或旋转等。
使用SpecAugment,屏蔽频谱图的某个部分,有两种方式:
Frequency mask:使用水平条随机屏蔽一系列连续频率
Time mask:使用垂直条随机屏蔽一段时间范围
原始音频增强
Time shift:将音频向左或向右移动一个随机量(对于没有特定顺序的交通或海浪等声音,音频可以环绕;对于顺序很重要的人类语音等声音,间隙可以用静音填充)
Pitch shift:随机修改声音部分的频率
Time stretch:随机放慢或加快声音
Add noise:为声音添加一些随机值